
Künstliche Intelligenz gilt als Schlüsseltechnologie und zentraler Wettbewerbsfaktor für immer mehr Unternehmen. Kaum eine Branche, die nicht intensiv an ihrer Nutzung forscht. Aber ist ihre Anwendung auch sicher? KI ist nicht nur eine Frage des Rechts. Letztlich muss sie auch technisch über alle Prozessphasen von der Hardware bis zur Software umgesetzt werden, um sie autonom im Sinne von Confidential Computing nutzen zu können.
Der Begriff digitale Autonomie mag hochtrabend klingen. Doch dahinter verbirgt sich oft genug nicht weniger als die Existenzgrundlage eines Unternehmens. Geistiges Eigentum, unternehmenskritische Informationen oder sensible personenbezogene Daten sind ein gefundenes Fressen für Einflussversuche aller Art, von der Industriespionage bis zur Cyber-Erpressung.
Aber es muss ja nicht immer gleich ein so dramatisches Szenario sein. Nicht selten ist die Nutzung von KI einfach mit einem mulmigen Gefühl der Unsicherheit verbunden, wenn beispielsweise ein für die Entwicklung eigener generativer KI-Anwendungen wichtiges Large Language Model (LLM) exklusiv auf dem Portal eines bestimmten Hyperscalers verfügbar ist. Denn wer weiss schon, was in einer solchen proprietären Umgebung mit den eigenen wertvollen oder vielleicht sicherheitssensiblen Daten im Hintergrund passiert? Oder noch provokanter gefragt: Inwieweit gehört die Nutzung und Weitergabe dieser Daten sogar zum Geschäftsmodell des Betreibers?
Open Source und das Zwiebelschalen-Prinzip
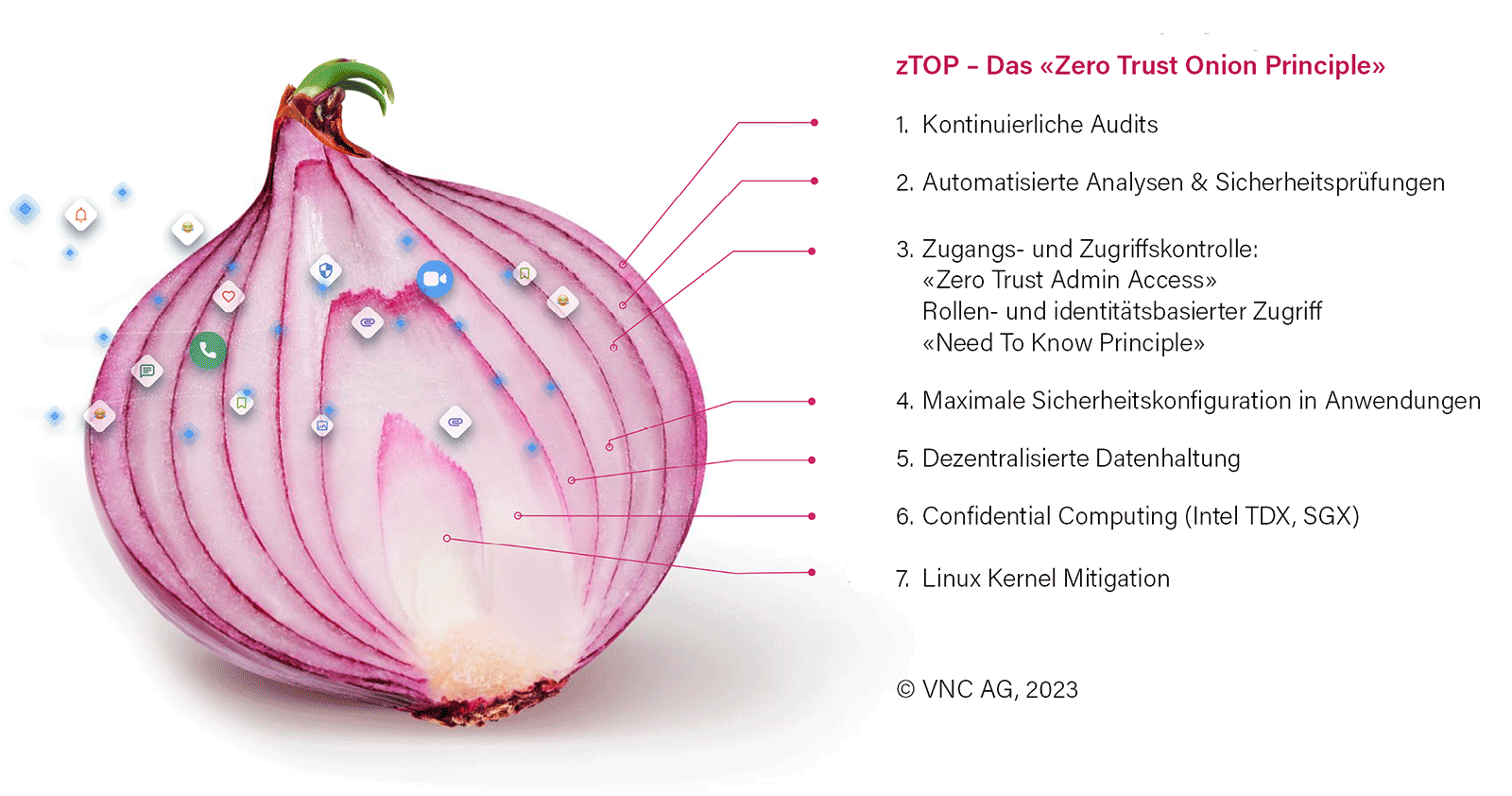
Die erste Konsequenz muss es daher sein, intransparente proprietäre Architekturen zu meiden und stattdessen quelloffene Software und Systeme zu nutzen. Sicherheit und Souveränität können aber nur dann erreicht werden, wenn sie Ende-zu-Ende, sprich über die gesamte Prozesskette hinweg gedacht werden. Proprietäre Plattformen sind dabei nur ein kleiner, wenn auch wichtiger Teil. Es reicht ja schon, wenn ein potenzielles Datenleck an einer einzigen, vielleicht winzigen Stelle vorhanden ist. Um das auszuschliessen, müssen alle Ebenen einer IT-Architektur gesondert gesichert werden. Vorbild dafür ist das Zero Trust Onion Principle (zTOP). Wie bei einer Zwiebel wird die IT-Architektur dabei in insgesamt sieben „Schalen“ unterteilt, für die jeweils die Hürden für potenzielle Intrusionen auf das technisch höchste Niveau gesetzt werden:
- Prozessor-Ebene: Die innerste Schale des zTOP-Konzepts betrifft den Linux-Kernel. Er wird so gesichert, dass die Linux-Funktionen ohne Limitierungen auf Prozessor-Ebene verfügbar sind und damit die volle Prozessorleistung genutzt werden kann.
- VM-Ebene: Auf der nächsten Ebene wird die Kubernetes Infrastruktur in eigenen, besonders gesicherten Enklaven geschützt. So wird sichergestellt, dass die darin befindlichen Daten nur von den berechtigten Anwendungen genutzt werden. Das gleiche Prinzip gilt auch für den Schutz besonders sensibler Daten im Arbeitsspeicher eines Rechners. Sie werden dort verschlüsselt und sind so vor unberechtigten Zugriffen gesichert.
- Datenbank-Ebene: Zentrale Datenbanken sind ein latentes Sicherheitsrisiko. Es kann abgefangen werden durch ein dezentrales Daten-Handling, bei dem die Daten in verschiedenen Rechenzentren vorgehalten und ständig untereinander abgeglichen (repliziert) werden.
- Directory-Management: Auf Schale vier geht es um die maximale Sicherheitskonfiguration für Anwendungen und die Vorgaben für den autorisierten Datenzugriff. Sie betrifft sowohl die Nutzer als auch die Administratoren. Für beide Nutzergruppen werden im Directory-Management rollen- basierte Zugriffsrechte definiert und kontrolliert. Sie können sowohl personenbezogen als auch für Teams oder Abteilungen vorgenommen und gegebenenfalls eingeschränkt werden.
- Zugangsmanagement: Die fünfte Schale betrifft das Zugangsmanagement. Dabei steuert das Need-to-know-Prinzip den personalisierten, autorisierten Zugang zu Informationen. Ein intelligentes Berechtigungsmanagement sorgt dafür, dass nur genau die Daten und Informationen zugänglich sind, für die das jeweilige Nutzerprofil autorisiert ist. Alle anderen Daten sind vom Zugriff automatisch ausgeschlossen und gesperrt.
- Automatisierte Analysen und Sicherheitschecks: Auf der vorletzten Stufe werden automatisierte Analysen und Sicherheitschecks durchgeführt. Das Identity Management sorgt für laufende Sicherheitsüberprüfungen und das Update der mit den Rollen verbundenen Zugriffsrechte.
- Auditierbarkeit: Alle diese Massnahmen müssen in der siebten Stufe jederzeit und unabhängig auditierbar sein. Das wiederum setzt Open Source als Quellcode voraus, da nur quelloffene Software jederzeit unabhängig auditiert werden kann. Im zTOP-Konzept erfolgen diese Audits nicht iterativ, sondern laufend.
Wir bewegen uns also in einem aufeinander abgestimmten
Sicherheitssystem von der Hardware-Ebene (Prozessoren, Server, Rechenzentren) über virtualisierte Maschinen und Middleware bis hin zur Applikationsebene mit dem Ziel, den bestmöglichen Schutz zu erreichen. Und genau hier, bei den Anwendungen, kommt Künstliche Intelligenz ins Spiel.
KI und Confidential Computing auf Applikationsebene
Die Crux bei der Anreicherung von Software mit KI-Funktionen oder der Entwicklung eigener KI-Anwendungen ist die oben beschriebene Tatsache, dass viele der dafür benötigten generativen KI-Werkzeuge nicht frei verfügbar sind. Das betrifft vor allem die Large Language Models (LLMs), die die Grundlage dafür liefern. Vielmehr sind sie häufig an bestimmte, herstellerexklusive Plattformen gebunden.
Aber es gibt einen cleveren Weg, sie trotzdem unabhängig davon zu nutzen. So können KI-Funktionen in Anwendungen eingesetzt werden, ohne Datenabgriff befürchten zu müssen. Der Zugriff auf die generativen KI-Systeme erfolgt dabei direkt aus den Applikationen heraus. Dazu werden die entsprechenden Large-Language-Modelle nicht auf den Service-Plattformen der KI-Anbieter genutzt, sondern vielmehr Open-Source-Toolkits wie beispielsweise OpenVINO eingesetzt. Damit ist es möglich, die LLMs direkt auf dem lokalen PC oder dem mobilen Endgerät auszuführen. Dadurch sind sowohl die entsprechenden Applikationen als auch die in den LLMs genutzten und verarbeiteten Daten vor unbefugten Zugriffen aller Art geschützt.
Die ideale Basis dafür ist eine modulare Applikationsplattform. Das beschriebene Toolkit wird dabei tief in den Software-Stack eingebettet. Dadurch können potenziell alle Anwendungsmodule von der KI-Unterstützung profitieren, auch so vermeintlich alltägliche Kommunikations- und Kollaborations-Applikationen wie Projekt-Management, Chat oder Videoconferencing.
Die in die verschiedenen Anwendungen integrierten KI-Assistenten stehen somit modulübergreifend mit ihren generativen KI-Funktionen und -Services zur Verfügung. Gleichzeitig haben sie überall das gleiche Look-and-Feel und die gleiche Bedienlogik, was ihren produktiven Einsatz ebenso erleichtert wie die Nutzung durch die Anwender.
Gleiches gilt auch für die darauf aufbauenden KI-gestützten Anwendungen wie etwa Enterprise Knowledge Management oder Robot Assistants. Intelligente Suchfunktionen und automatisierte Assistenten, die lokal auf dem eigenen PC laufen, erleichtern so nicht nur die Arbeit, sie schützen die Anwender auch vor dem Abgreifen ihrer Daten und tragen so zur Demokratisierung generativer KI bei. Für Unternehmen bedeutet die Kombination aus Open Source und lokaler Nutzung von generativen KI-Modellen Sicherheit bei der Integration von Künstlicher Intelligenz in ihre Workflows und Geschäftsmodelle.
Die Autorin

Andrea Wörrlein ist Verwaltungsrätin der VNC AG in Zug. Sie ist Mitbegründerin des Unternehmens und gehört dem Zug International Women's Club (ZIWC) an.
Publikation in Zusammenarbeit mit:

Der Beitrag erschien im topsoft Fachmagazin 24-2
Das Schweizer Fachmagazin für Digitales Business kostenlos abonnieren
Abonnieren Sie das topsoft Fachmagazin kostenlos. 4 x im Jahr in Ihrem Briefkasten.